
![]()
Depuis l´arrivée d´AMD avec son architecture K7, que l´on trouve actuellement sur les processeurs Athlon et Duron, Intel à perdu de sa grandeur. Entre une architecture P6 vieillissante et un échec total de l´i820 et de la Rambus, le géant de Santa Clara ne savait plus trop où donner de la tête. C´est dans ce contexte plus ou moins chaotique qu´Intel lance donc le Pentium 4, premier processeur à être doté de la toute nouvelle architecture NetBurst qui est censée être l´apogée du x86 chez Intel.
Depuis quelques mois, l´architecture P6 montrait ses limites. En effet, malgré des processus de fabrications très perfectionnés, Intel ne pouvait clairement pas suivre AMD et son architecture K7 en terme de fréquence.
Mais il ne faut pas oublier que si l´architecture K7 à été introduite Mi 1999 avec un Athlon à 500 MHz fabriqué en 0.25 Micron, l´architecture P6 est pour sa part apparue dès 1995 avec le Pentium Pro 150 MHz, qui était gravé en 0.6 Micron ! On ne peut donc quêtre impressionné par la longévité de cette architecture, et par le travail des ingénieurs de fabrication d´Intel.
Toutefois, il était clairement temps pour Intel de passer à une nouvelle étape, chose désormais faite avec l´architecture NetBurst.
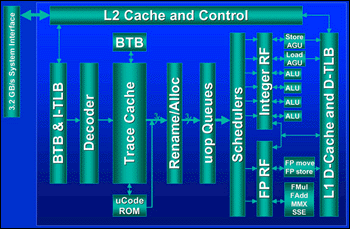
L´architecture NetBurst se distingue notamment par une profondeur de pipeline jamais atteinte à ce jour par un processeur x86, puisqu´elle est de 20 niveaux, contre 10 par exemple pour une architecture de type P6. A titre de rappel, un pipeline est un ensemble d´unités effectuant un travail à la chaîne, dans le but final de traiter les instructions. Lorsque l´on augmente la profondeur du pipeline, on augmente le nombre d´unités, et on réduit donc le travail que chacune doit effectuer. Cela à des avantages, mais aussi des inconvénients.
La bonne nouvelle, c´est que l´augmentation de la profondeur du pipeline permet d´augmenter la fréquence facilement et sans changement de technologie immédiat. En effet, chacune des taches effectuées par les unités étant moins lourde et nécessitant un nombre moindre de transistor, il est possible de l´effectuer en un temps plus court.
Imaginez un processeur à 2 niveaux de pipeline ... si un de ces niveaux ne peut être passé en moins de 0.5 secondes du fait de limites purement physiques, ce processeur ne pourra fonctionner à plus de 2 Hz. Maintenant, si vous passez à 4 niveau de pipeline, avec un temps maximum de 0.3 secondes pour le passage d´un de ces niveaux, vous pourrez monter à 3.33 Hz, tout en conservant les mêmes techniques de fabrication.
Malheureusement, le fait d´augmenter la profondeur du pipeline à aussi un impact négatif sur l´IPC du processeur (L´IPC, ou Instruction Per Clock, mesure en fait l´efficacité du processeur, c´est à dire le nombre d´instructions pouvant être traité par cycle d´horloge).
Pourquoi ? Le processeur exécute des instructions ... or il est possible que la suite d´un programme, et donc des instructions à exécuter, soit dépendante de ce que l´on appelle un test. Par exemple, si A > B alors faire A + B, sinon faire A - B. Or, dans un processeur utilisant un pipeline, il faut commencer à traiter l´instruction suivant le test avant d´en connaître le résultat, ceci afin d´alimenter continuellement le pipeline. Pour choisir si l´on doit exécuter l´une ou l´autre des instructions, on utilise ce que l´on appelle la prédiction de branchement.
La prédiction de branchement utilise un principe assez simple. En effet, la plupart du temps le processeur exécute des suites d´instructions qu´il a déjà rencontré peu auparavant, et donc des tests dont il connaît déjà l´issue probable. Le processeur va donc stocker dans ce que l´on appelle le BTB (Branch target buffer) l´historique des tests déjà traités. S´il rencontre un test du même type, il prendra le branchement déjà pris auparavant. Cette technique est plutôt efficace, avec un taux de réussite d´environ 93% sur Pentium 4 (BTB de 4 Ko) , contre 90% sur Pentium III (BTB de 512 octets).
Malheureusement, chaque échec a un impact très important sur les performances, puisque s´il y´a eu une mauvaise prédiction de branchement le pipeline doit être remis à zéro afin de recommencer avec le bon branchement. Vous comprendrez donc que cela est plus pénalisant avec un pipeline à 20 niveaux qu´un autre à 10 !
Il est à noter que l´architecture NetBurst est également capable d´exécuter les instructions dans le désordre (out of order execution). Ainsi, si par exemple la première ALU traite le calcul A = 5 x 6 et que le calcul suivant est B = A + 2; la seconde ALU ne peut rien faire dans le cas d´une exécution in order (dans l´ordre), si ce n´est attendre le résultat du calcul A. Avec un le système out of order, la deuxième ALU peut sauter ce calcul pour passer à un suivant, tous les résultats étant bien sur remis dans l´ordre à la fin.
Côté ALU et FPU, l´architecture NetBurst n´apporte pas grand chose à première vue par rapport à l´architecture P6, puisqu´on y retrouve deux ALU (Arithmetic Logic Unit) et une FPU (Floating Point Unit), ce qui correspond tout de même à une architecture dite super scalaire. Toutefois, et c´est la principale innovation apportée par l´architecture NetBurst à ce niveau, les deux ALU fonctionnent à une vitesse double de celle de la fréquence du processeur. Ainsi, il est possible d´exécuter jusqu´a quatre instructions par cycle via ces ALU, contre deux auparavant.
Les caches ont également évolué. Tout d´abord, le cache L1 ne comprend plus qu´un L1 Data cache, qui ne fait d´ailleurs que 8 Ko. En fait, le L1 Instruction cache se prénomme désormais Instruction Trace Cache. Plus qu´un simple cache bête et méchant, le Trace Cache stocke les instructions après la conversion x86 -> micro-ops, et dans l´ordre dans lequel elles devraient être utilisées; ce qui permet d´une part d´économiser en cycles processeur en cas de mauvaise prédiction de branchement (pas besoin de re convertir les instructions) et d´autre part d´avoir accès aux instructions devant être utilisées plus rapidement. A noter qu´Intel ne communique pas sur la taille en Ko de ce cache, mais sur le nombre de micro-ops qu´il peut contenir, c´est à dire 12 000. Il est à noter que la vitesse du cache L1 est également améliorée. Le temps de latence passe ainsi de 3 ns (PIII 1 GHz) à 1.4 ns (P4 1.4 GHz) et la bande passante de 14.9 à 41.7 Go /s.
Si la taille du cache L2 reste inchangée par rapport à celui des derniers Pentium III, c´est à dire 256 Ko, c´est là encore différent pour la vitesse. En effet, on passe là encore d´une bande passante de 14.9 Go /s pour un PIII 1 GHz à 41.7 Go /s pour un P4 1.4 GHz.
Amd / Benchmark XP / Benchmark Atlon / Comparasions / Mon opinion / Overclocking /Liens /Contact / Vote
Copyright © 2001 Mathieu Rodrigue. All rights reserved.